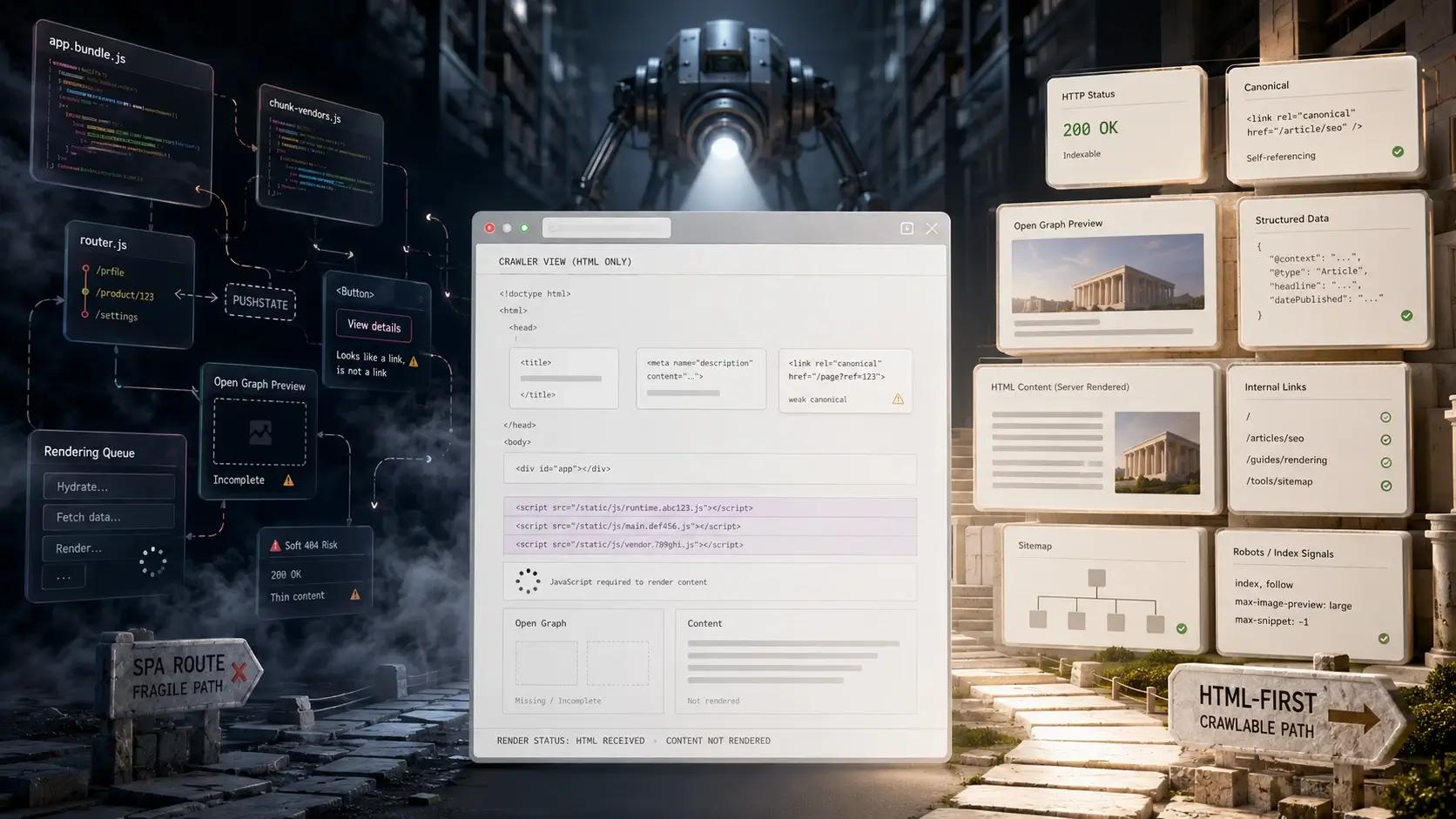
A pure, client-side rendered Single Page Application is, for general SEO, usually the wrong tool dressed up in fashionable clothes. It feels modern. It feels clever. It gives developers that lovely sensation that everything is an 'app', even when the thing being built is really just a website with articles, services, products, locations, and pages that need to be found by ordinary humans through search.
The issue is not that Google is some poor, confused little machine sitting in the corner, unable to understand JavaScript. That would be too simple, and as usual in SEO, too convenient. Google can process JavaScript web apps, and its own documentation says Google Search processes JavaScript through crawling, rendering, and indexing.[1] The issue is that a pure SPA makes every crawler work harder than it needs to work. It makes Google render. It makes links less obvious. It makes metadata more fragile. It makes status codes messy. It makes social previews unreliable. It creates, in the truest sense, a needless dependency on the browser to assemble what should have been available in the first server response.
That is the ground zero problem. A website that depends on organic search should not ask a crawler to build the page before it can understand the page. A crawler is not your unpaid front-end engineer.
The Empty Shell Problem
Google describes a common JavaScript pattern where the initial HTML does not contain the actual page content, and Google must execute JavaScript before it can see the content generated by the app.[1] That is the app shell model, and for SEO it is often the first crack in the wall.
Google explains that some JavaScript sites use an app shell model where the initial HTML does not contain the actual content, meaning Google needs to execute JavaScript before it can see what the page actually contains.[1]
On a traditional HTML page, the important material is there when the crawler arrives. The page title, the heading, the body copy, the internal links, the canonical, the robots directive, the structured data, and often the Open Graph tags are all present in the first response. The crawler can fetch the URL and immediately begin to understand what it is looking at.
With a pure SPA, the crawler may receive a thin document, a root container, and several JavaScript files. The actual page then appears only after scripts are downloaded, parsed, executed, and allowed to call whatever data they need. When it works, lovely. When it does not, you have a beautiful website for humans and a fog machine for search engines.
| SEO signal | Where it should live | What often happens in a pure SPA |
|---|---|---|
| Main content | In the initial HTML response | It appears only after JavaScript renders the route. |
| Internal links | In crawlable <a href="..."> elements |
Navigation is handled through buttons, script events, or framework routing. |
| Canonical URL | In stable HTML metadata | It may be injected or changed after rendering. |
| Error status | Returned by the server | The server returns 200 OK for routes that are actually missing. |
| Social metadata | In server-rendered Open Graph tags | Bots may see generic or missing preview data. |
This is where the fashionable simplicity of the SPA becomes a kind of technical debt. You have not removed complexity. You have moved it from the server, where search engines expect clarity, into the client, where every crawler has to play catch-up.
The Rendering Queue Is Not A Strategy
Google’s JavaScript SEO documentation says Googlebot queues pages for crawling and rendering. It fetches a URL, parses the HTML response, extracts URLs from href attributes, and then, where rendering is needed, waits until resources allow a headless Chromium system to render the page and execute the JavaScript.[1]
The phrase 'until resources allow' should make any serious SEO stop and breathe for a moment. It means rendering is not the same thing as fetching HTML. It is a second stage. It costs more. It depends on more moving parts. It can take longer. Google says a page may stay in the rendering queue for a few seconds, but it can take longer than that.[1]
For a static brochure page, maybe that delay is not the end of the world. For a business that depends on fast discovery, fresh content, seasonal pages, ecommerce stock, news, events, offers, or rapidly changing service pages, that delay is not a charming little detail. It is drag. It is friction. It is the website equivalent of asking the postman to assemble the envelope before he can read the address.
The old phrase 'two-wave indexing' is not perfect, because Google’s systems are more fluid than a simple two-step diagram. But the practical lesson still holds. If the useful page only exists after rendering, then you have made the search engine wait for the useful page. That may be acceptable for a logged-in dashboard. It is a poor default for public pages that need to rank.
Crawl Budget Is Really About Respecting The Machine
Crawl budget is often abused in SEO talk, usually by people trying to make a small five-page website sound like Amazon. Google is clear that most publishers do not need to obsess over crawl budget if their pages are crawled the same day they are published and the site is not large or rapidly changing.[3]
Still, the principle matters. Google’s crawling documentation explains that the web is too large for Google to explore and index every available URL, so there are limits to how much time crawlers can spend on a single hostname.[3] Google defines crawl budget through crawl capacity and crawl demand, and says that making pages efficient to load can help Google load and render more content from a site.[3]
This is why pure SPAs become especially risky on larger sites. Every extra JavaScript bundle, duplicate route, client-side state, soft 404, blocked resource, and unstable API call makes crawling less efficient. It may not hurt a tiny site immediately, but it builds a bad foundation. And bad foundations, as builders and SEOs both know, rarely announce themselves politely. They wait until the structure is large enough to embarrass you.
- Do not assume that because Google can render JavaScript, every search engine, social crawler, AI scraper, or audit tool will render it correctly.
- Do not put essential content, links, or canonical signals exclusively behind client-side execution.
- Do not treat a `200 OK` response as acceptable for every route in a client-side app.
Client-Side Routing Often Breaks The Internal Link Graph
Google’s link guidance is wonderfully blunt. Generally, Google can only crawl a link if it is an <a> HTML element with an href attribute.[2] Google also says that links in other formats usually will not be parsed and extracted reliably, including elements that only behave like links because of script events.[2]
This is where SPAs often take the mickey. The user sees navigation. The crawler sees theatre. A button with an onclick event may move a human from one view to another, but it is not the same as a crawlable link. A framework-only routing attribute may look tidy in the codebase, but Google specifically recommends proper anchor elements with real href values for crawlable links.[2]
| Pattern | Search implication |
|---|---|
<a href="/seo-services">SEO services</a> |
This is the clean, crawlable pattern Google recommends.[2] |
<button onclick="goTo('/seo-services')">SEO services</button> |
The destination is hidden inside script behaviour, so it is not reliably crawlable.[2] |
<a routerLink="/seo-services">SEO services</a> |
Google lists framework-style link attributes as not recommended for reliable crawling.[2] |
<a href="#/seo-services">SEO services</a> |
Google warns SPA developers not to use fragments to load different page content.[1] |
The internal link graph is one of the oldest and most practical pieces of SEO. Pages need URLs. Important URLs need internal links. Anchor text should explain what the target page is about. This is not old-fashioned. It is the basic plumbing of the web.
Soft 404s Are A Symptom Of Server Confusion
A search engine needs the server to tell the truth. If a page is gone, return a 404 or 410. If it has moved, return a redirect. If access is restricted, return the appropriate status. The browser interface is not enough. The server response matters.
Pure SPAs often return 200 OK for every route because the server hands everything to the same application shell. The client-side router then decides whether the user sees a product, a category, an article, or a 'not found' screen. Google warns that, in client-side rendered SPAs, meaningful HTTP status codes can be impossible or impractical, and this can lead to soft 404 errors.[1]
Google’s JavaScript troubleshooting documentation says this can be especially difficult in SPAs because client-side JavaScript may report a 200 status code instead of the appropriate status code, which can lead to error pages being indexed and possibly shown in search results.[4] Google’s crawl budget documentation also says soft 404 pages continue to be crawled and waste budget.[3]
That is not a minor implementation detail. That is your site saying, with a straight face, that a dead page is alive. Search engines do not tend to reward that kind of existential confusion.
Metadata Should Not Be Left To The Client
Titles, meta descriptions, canonicals, robots directives, structured data, hreflang, and Open Graph tags are not decorative trinkets. They are machine-readable signals. They help search engines cluster, index, display, and share the page correctly.
Google says unique titles and meta descriptions help users identify the best result for their goal, and it allows JavaScript to set or change them.[1] But permissive guidance is not the same as best practice. Google also says the best way to set the canonical URL is with HTML, and warns against using JavaScript to change the canonical to something different from the original HTML.[1]
Social platforms make the same point from another angle. Meta says most content is shared to Facebook as a URL, and that Open Graph tags are important if you want to control how content appears when shared.[5] Without Open Graph tags, the Facebook crawler uses internal heuristics to guess the title, description, and image.[5]
So yes, a SPA may eventually inject the right title. It may eventually inject the right Open Graph tags. It may eventually set the canonical. But 'eventually' is not a standard I would build a search strategy around. If the metadata matters, render it in the HTML response.
What To Use Instead
The answer is not to throw JavaScript into the sea, although there are mornings when that does feel emotionally attractive. JavaScript is not the enemy. Misusing it as the foundation for every public page is the problem.
Google says dynamic rendering is a workaround rather than a long-term solution, and recommends server-side rendering, static rendering, or hydration instead.[6] The web.dev rendering guidance similarly encourages developers to consider server-side rendering or static rendering over a full rehydration approach.[7]
| Architecture | Where it fits | SEO judgement |
|---|---|---|
| Pure client-side SPA | Logged-in dashboards, internal tools, complex app experiences, account areas. | Fine when the content is not meant to rank. Weak as a default for public SEO pages. |
| Static rendering | Articles, guides, landing pages, locations, evergreen pages, documentation. | Excellent when URLs are predictable and content can be generated ahead of time. |
| Server-side rendering | Dynamic public pages, ecommerce, service pages, fast-changing templates. | Strong when the server returns complete HTML, metadata, and correct status codes. |
| Hybrid rendering | Most serious commercial websites. | Usually the best balance, because indexable pages get HTML and app-like areas keep interactivity. |
A sane SEO architecture is not complicated. Serve the essential page before JavaScript runs. Put the main content in HTML. Use real links. Return real status codes. Put canonical and social metadata in the server response. Use JavaScript to enrich the experience, not to hide the experience until a crawler does extra work.
- Use server-side rendering or static rendering for public pages that need to rank.
- Keep important navigation as crawlable` links.
- Return proper 404, 410, 301, 302, and 200 status codes from the server.
- Render titles, descriptions, canonicals, robots directives, structured data, and Open Graph tags in HTML.
- Test important URLs in Google’s URL Inspection Tool or Rich Results Test, because Google recommends these tools for reviewing rendered DOM, loaded resources, and JavaScript errors.[4]
The Real Rule
The real rule is simple: if a page needs to rank, the page should exist before JavaScript runs.
That one sentence cuts through a great deal of industry fog. A pure SPA may be fine for the private part of a platform. It may be perfect for a dashboard, a booking interface, or a complex user workflow. But for general SEO, where the job is to make pages discoverable, understandable, indexable, shareable, and citable, a pure client-side SPA is an unnecessary risk.
Google can render JavaScript. That does not mean you should force it to. Other crawlers may not render JavaScript at all.[6] Social crawlers need explicit metadata.[5] Google needs crawlable links.[2] Soft 404s waste crawling resources.[3] These are not opinions. They are the shape of the web, whether the latest framework discourse likes it or not.
So build the app where an app is needed. But build the website as a website. HTML first. JavaScript second. Search visibility depends on that order.
References
- Google Search Central: Understand JavaScript SEO Basics
- Google Search Central: Link Best Practices for Google
- Google Crawling Infrastructure: Optimise Your Crawl Budget
- Google Search Central: Fix Search-related JavaScript Problems
- Meta for Developers: A Guide to Sharing for Webmasters
- Google Search Central: Dynamic Rendering as a Workaround
- web.dev: Rendering on the Web


